RISCV-CPU presentation

一、前言
我的时间不多了,特地开此一篇为我的CPU项目收尾,也方便在正式秋招的时候进行复习。然后安心投入到其他重要事务当中。
当前项目的完成情况如下所示:
1)采用verilog语言编写,在linux vivado平台上完成了仿真与验证。
2)采取四级流水线模型实现,四级流水线包括取指,译码,执行,写回。去除访存阶段以后,在执行阶段完成访存请求并提交给写回级。
3)在流水线之间实现了握手协议,支持插入气泡解决结构冒险和指令Hazard。 采取旁路机制避免数据冒险,减少流水线气泡。采用冲刷机制和静态分支预测抵消控制冒险。
4)完整支持RV32 IM指令集,已通过RISC-V官方compliance test验证。为验证cpu在测试集上的表现编写了一系列python自动化测试脚本,用到开源EDA iverilog + gtkwave 实现建模,仿真与功能验证。
5)实现了双周期乘法器和多周期除法器。支持连续同构乘除法指令融合,提高流水线运行效率。乘法器采用七层华莱士树+ 2位booth编码实现。除法采用迭代试商法实现。
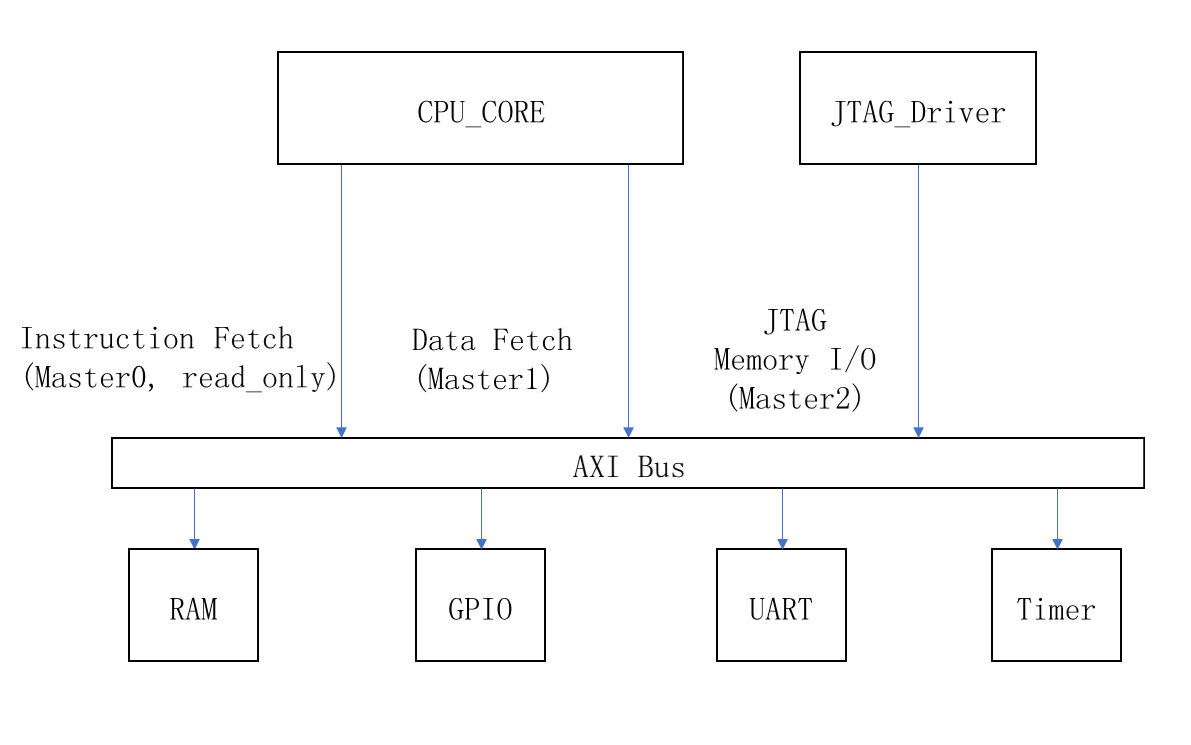
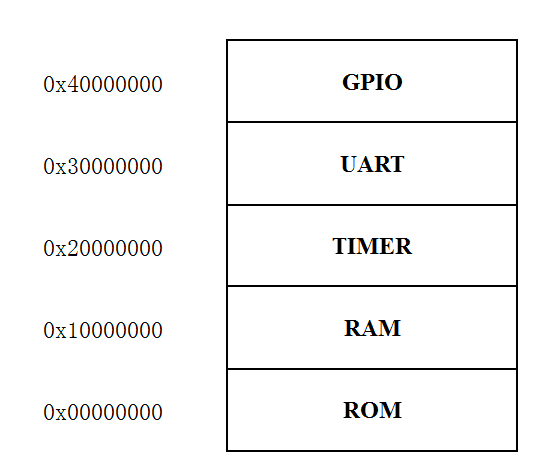
6)集成了类AXI总线,支持MMIO方式挂载外设,现有外设包括MEMORY,GPIO,UART。
7) 集成了一块大小为1KB的两路组相连I-Cache,减少在总线上反复取指的时间开销,core流水线可以全速运行。
8) 集成jtag模块用于下载程序,在Arty Artix-7 FPGA平台上跑通了LED点灯C语言例程。
9) 定位若干设计缺陷,采取一系列策略修复时序违例,将最大主频从43Mhz优化到了100Mhz。加入Cache以后,slack裕量不足,目前主频最大62Mhz(参考 Setup slack)
未来的项目更新打算和计划变更情况如下
1)调试coremark程序,获得评分(完成)
2)添加memory missalign 异常检测
3)优化Cache,缩短关键路径(完成,访存全部打一拍)
4)增加一级取指,支持2比特计数器分支预测(完成一般,增加pc 没有加取指)
5)支持乱序发射顺序提交feature,尽可能复用EX阶段的资源
6)支持双发射
7) 进行软件建模,为大size的program debug做准备
8)支持MMU,跑起linux!太帅了
该CPU的开源网址如下:
https://github.com/Rzfly/simple_riscv_soft_core/
该CPU项目的原创情况如下:
1)RTL部分,JTAG module并没有完全消化,本人只是对DM进行了支持握手协议的改造,这一块的知识产权要归tinyriscv的作者。其他module或多或少已经被我魔改,尤其是总线与Core。
2)软件部分,测试集的编译参数是参考通用情况的,并没有应用tinyriscv的地址分配,所以也谈不上非原创。测试程序的编译是参考了tinyriscv的参数,所以访存地址取决于驱动宏文件里的内存空间分配,还算可以消化,可以自己重新定义。但也不能算完全掌握,汇编程序的引导部分还有待进一步研究消化。
二、基于功能的项目结构框图
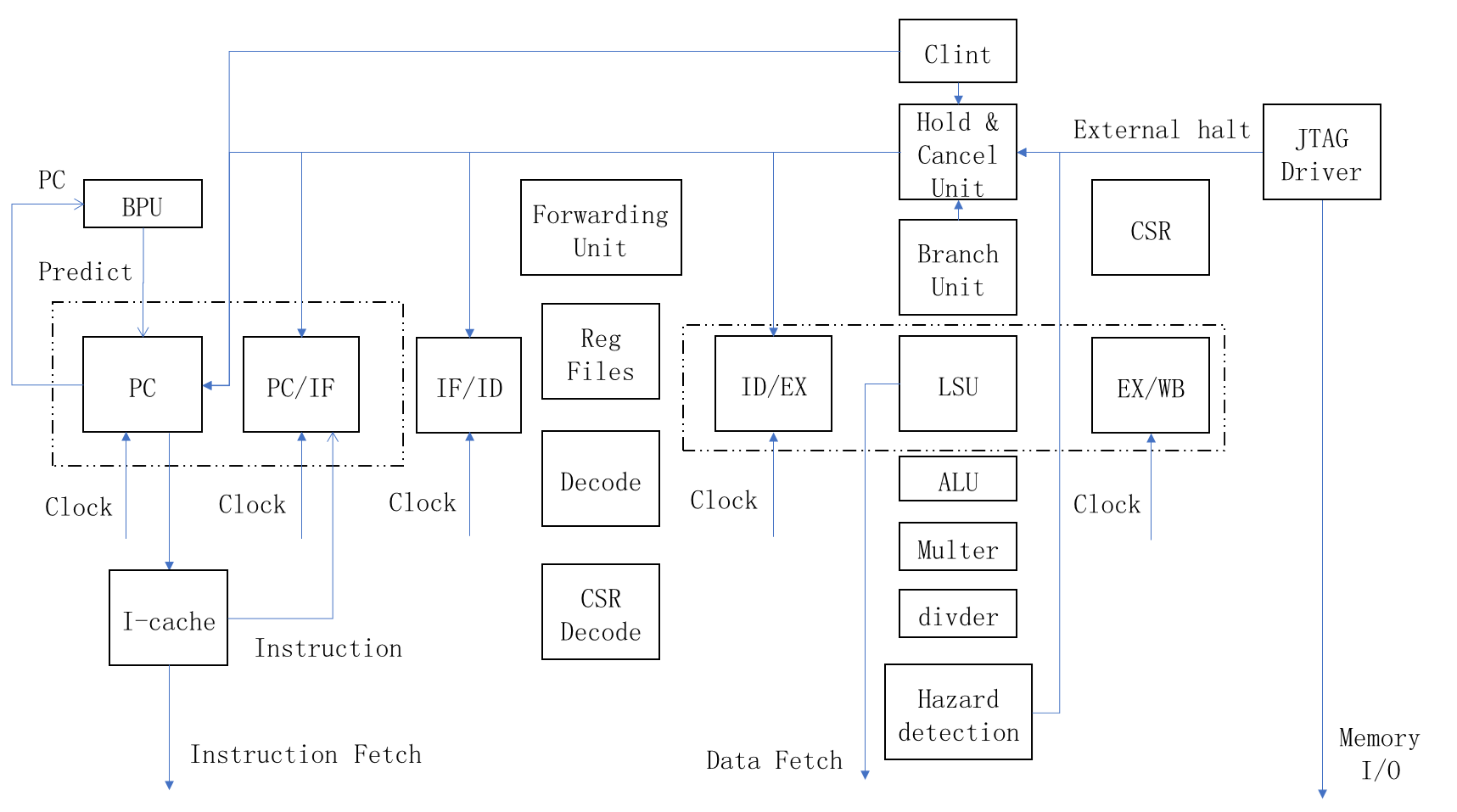
图中以虚线框住的部分,是涉及总线请求与响应处理的单元,做了相对复杂的设计。具体来说,当总线请求握手成功,可以交付下一流水级。当数据握手成功,下一流水级才可以继续向后交付。
如图所示,Forwarding单元不仅针对reg files 还针对csr regs。Hazard dection处理两种情况,一种是read after load相关,另一种是 forwarding not valid相关。
图中没有画出I-cache,Multer,Divider,有待更新。
clint支持的中断类型只有一种,即外部timer中断,暂时不支持中断嵌套,一次只相应一种中断。支持检测的异常仅包括RV32I指令异常。有关特权模式的指令一律处理为机器模式的指令。
不知道为什么,竟然没有面试官问JTAG。带JTAG的总线仲裁机制其实也是我这个CPU的特色(浪费资源的点,笑)。
三、项目关键优化点
1)为什么使用四级流水线?
节约资源,避免Forwarding引入超长路径。这其实是设计上的失误,一开始我把Forwarding放在EX级,所以Forwarding会导致rd_reg到mem_address_reg路径很长。其实Forwarding放在ID级就没事。
反正改都改了,凸显特色也没什么不好。在很多参考设计里,访存级本来也是要拿掉的,如果不拿掉的话,在多发射非访存指令的时候就会引入多余的延迟(尽管不影响吞吐量,但是影响功耗)。
2)为什么使用流水线握手机制?
为了适应变速的流水线,访存和取指有可能是多周期完成,因此流水线是变速的。在没有握手机制的流水线上,变速的流水线可能会引入一些错误,执行指令失效,Forwarding失效。
握手机制还能提供控制功耗的接口。
值得一提的是流水线冲刷情况下对取指阶段的处理,设计了额外的状态丢弃无用的返回数据,保护了流水线的正常运行。
在其他状态下,取指阶段是一个zero bubble pipeline skid buffer。写回阶段亦如是。
3)为什么使用双周期乘法器?为什么支持乘除法指令融合?
答:单周期乘法器恰好不满足时序约束。这是RV推荐实现的特性之一。
4)为什么使用类AXI总线?
答:最初的总线是零延时访存的,大量组合逻辑引入延时。采用AXI的目的之一是断开关键路径,所以最大主频一度达到100Mhz。AXI的另一个作用是读写通道分离,来自core的二读一写三通道最大程度上利用了memory的带宽,使得流水线可以全速运行(但是很遗憾引入了访存延迟,这一点并没有实现,只有依靠cache)。
多通道类AXI总线一定程度上代替了CrossBar。
当然,为了学习AXI协议也是很重要的原因。在实现突发读操作时,在memory侧加入了同步fifo,虽然花费了资源,但是提高了读写性能,简化了设计。
5)为什么加入I-Cache?
答:为了尽可能地消除取指令的延迟。从五拍一取指,变为八拍四取指,当然是极大地提高了取指效率。在考虑分支跳转的情况下,就变为零延迟。可见在无穷大的程序运行时间里,取指令很有可能是零延迟。
Cache设计的三大要素
1.查找算法(映射算法)
本项目采取两路组相连映射。
组相连映射是指,内存的某一段映射到某一组(cacheline index)时,有两个候选项。
直接映射是指,内存的某一段映射到某一组(cacheline index)时,只有一个候选项。
全相连,内存的某一段映射到某一组(cacheline index)时,有N个候选项。并且N×(cacheline index) = cache size
这块1K的Cache是如此组织的。
512KB是每一路的大小,对应cacheline size*num.
linesize = 16Byte(offset = 4bit)
num = 32(index = 5bit)
2.替换算法(读策略)
替换算法是指,当cache不命中时,需要刷新既有的缓存来读入新的cacheline,选择cacheline的方法就是替换算法+cacheline index。
老有人问,LRU算法。可是我采取的是LFSR,基于伪随机数的替换法,容易实现,性能不差,没有利用局部性。
3.写策略
当cacheline处于dirty状态时,采取写回法。但是实际上没有实现。
这块Cache的状态机分为IDLE,LOOKUP,MISS,REPLACE,REFILL五个阶段。
平时工作在LOOKUP。不命中进入MISS,并且发起替换请求,当握手成功则进入REFILL。REPLACE是用于写DIRTY数据的,在I-cache用不到,直接进入到REFILL。Read Last则REFILL结束,允许新的请求和LOOKUP。
6)资源复用的尝试?
答:ALU复用了一个加法器和逻辑左移位单元,实现了RV32I指令集的一切算数和逻辑运算。ALU外还有一个加法器,用于计算跳转地址,在一些指令,比如jalr的情况下,两个加法器不得不都用到。
7)为什么加入JTAG?
答:不能下程序的CPU是假的CPU!我的CPU不是玩具。JTAG DM用两次req的机制读写memory(以system bus的方式下载程序,目前够用。虽然还有abstract command方式但是我没有支持,太难调试)。虽然不知道JTAG为什么这么别扭,但是我改成了在一次 read req中完成总线握手,把总线数据缓存到dm driver。供JTAG在第二次req的时候取走。
JTAG driver的工作时钟是外部输入的,所以涉及到跨时钟域处理问题,项目里采取的方法是双向握手DMUX,另外也需要相应的时序约束,值得学习。
(这么明显的考点,为什么没有面试官问???你们太业余了吧???)
注:tinyriscv的作者利用了ram的读保持特性和总线上的状态机标记来使得总线数据保留在总线上,不需要缓存到本地也能上传给JTAG上位机,而我的axi bus不支持这一特性(因为没有总线状态机,全靠固定仲裁),所以dm driver必须改成如上所述的缓存机制。
8)项目的复位处理?
答:这也是很花心思的一点。
目前在JTAG以外的部分采取同步复位,在JTAG时钟域里全采取了异步复位,日后计划全部改成异步复位。
之所以不采用异步复位,是因为在最初的设计里异步复位没有做同步释放处理,时序很差,干脆改成同步,好约束。类似的改动包括取消下降沿写reg,取消csr forwarding引起的timing loop,取消零延时总线仲裁引起的timing loop等等。
等到见识多了以后,我就理解了复位电路该如何设计,于是引入异步复位同步释放电路,充分享受异步复位带来的好处。
有关Xilinx复位白皮书的内容,可能在另一篇博客中进行总结。
继续说异步复位同步释放电路,由于项目中使用了PLL,带有locked输出和复位,所以内部复位信号是取决于locked信号的。一旦外部复位,必须等待PLL lock,内部的复位才可以结束。
在locked以后经过边沿检测,内部复位信号有效,再经过异步复位同步释放电路(4级FF)进行复位分发。
9)分支预测的效率
50%-》82%
6% cycles saving
BPU的存储组织方式是1024个ENTRY,将PC值和ENTRY的索引进行直接映射。
而不是采取链表的结构把PC值压缩在几个表项里。
因而不需要数量等同于ENTRY的比较器。
BHT=饱和计数器,用PC的一部分去索引,即直接映射。
BTB=分支目标缓存。一般很小。毕竟BHT也不是所有表项都记录了taken。