超标量处理器设计读书笔记-VM篇

第三章 虚拟存储器
3.1 概述
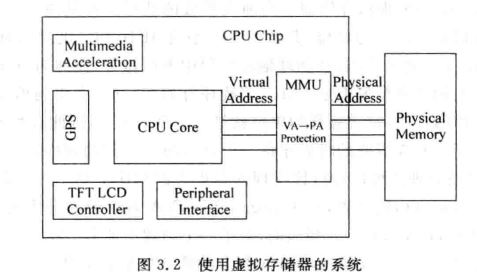
虚拟存储诞生的背景是,在现代处理器的场景下,操作系统每个进程需要更大的寻址空间以支持多进程应用。还可以实现子程序的保护和共享。
当物理内存不够用时,把不常用的页保存到下一级存储器当中,称为swap空间。实际内存大小为物理内存大小+swap空间大小。
3.2 地址转换
地址转换分为三种方式,线性页表,两级页表,多级页表。
3.2.1
当page不在物理内存中,就发生了page fault异常。为了减少异常发生的概率,应该尽可能使得常用的page留在物理内存当中。如果实现任意位置可以替换,相当于全相联的cache,但是代价昂贵,所以使用页表来存储VPN到PFN的转换关系。
指定程序的页表在物理内存中的位置的寄存器叫PTR。
线性页表的结构如下所示。
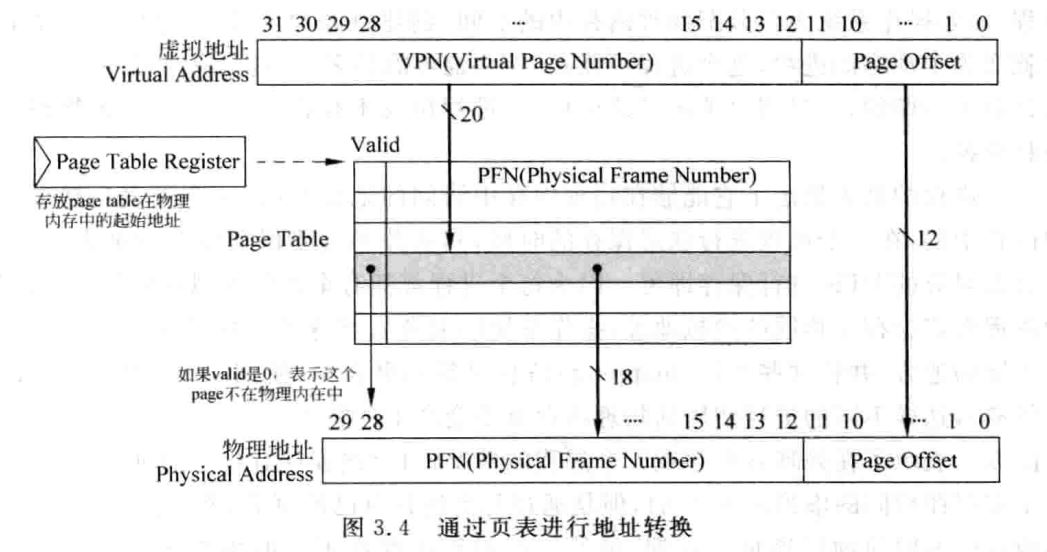
需要注意的是,entry内容除了PFN还有valid位。如果每个页表都保持对所有空间的映射,此时保存页表的空间十分巨大,因此需要进行多级映射。
在这个阶段,页表所在的物理内存地址是无需映射的,固定分配于内存。但是访存非常麻烦,要先访问页表得到物理地址,再按这个地址寻址,一共访问两次内存。现代处理器使用tlb和cache来加速这一过程。
3.2.2 多级页表
这种结构不需要把完整页表搬入内存,节约了空间。
此时VPN被分为VA1和VA2。VA1变化要创建新的页表,VA2变化要调用新的页。
这种结构使得不同程序占用的页表空间大小是不同的。由编译器处理可以使得程序占用的地址范围尽量集中。
页表的创建和维护,Page Walk Talk可以分硬件方案和软件方案。仍然需要PTR。
3.2.3 Page Fault
PF是异常的一种。处理PF的消耗巨大,一般用软件方案处理。
由于必然采用写回方案,因此需要为页表分配dirty位。注意,页表本身是一种写分配。
增加use位,并周期性地清零,实现近似的LRU算法。
MMU处理虚实转换和PF异常,并管理页表的标志位。
3.3 程序保护
增加页表项,实现地址空间的权限管理。
同时,有的地址空间是操作系统保留的,不需要地址转换。
3.4 加入TLB和Cache
目前为止,还没有解决多次访存取得PTE的问题。TLB就是为了解决这一性能损失。
缓存PTE的Cache称为TLB。TLB的数据一般只有时间相关性。
为了减少TLB丢失,一般采用全相连结构,容量不大。现代处理器当中,一般实现两级TLB。第一级包括I-TLB和D-TLB,全相联。第二级是组相联TLB。
1.处理TLB缺失
软件方案需要定义TLB缺失异常。然后从PTR来寻找正确的地址。
硬件方案由MMU的状态机解决,但是如果查到的PTE是无效的,那就只能Page Fault。
软件处理需要重新冲刷流水线取指令,硬件方案不需要重新取指令,只需要重启暂停的流水线。
2.写TLB
当TLB里的页被替换时,不能直接替换,而是先把PTE写回到页表。
页表PTE的use和dirty可能是过时的。如果页表和TLB的内容由不一致,需要先把TLB写回页表,再根据页表内容来替换页。否则,就只能通过TLB来替换页。后者的问题在于没有办法获得完整的内存分配信息。所以前者是必须解决的问题。
另一种解决办法是,假定TLB所有表项都是要被使用的。这样一来 从页表踢出一个页的时候,就不需要查找和更新TLB。
操作系统在写回一个dirty的页的时候,该页的最新内容可能不在物理内存而是在cache当中。此时OS有必要从D-cache找到这个内容并写回物理内存,需要OS能控制D-cache。
3.管理TLB
能将TLB的所有表项置为无效;能将TLB的某个ASID的对应表项置为无效;能将某个VPN的对应表项置为无效。不同处理器架构对此的实现不同,可以通过协处理器实现TLB控制。
ARM风格的管理,基于协处理器完成;
MIPS风格的管理,基于软件指令控制;
3.4.2 Cache的设计
1.Virtual Cache
VC把Cache置于TLB之前,节约了访问TLB的时间开销。但是引入了新的同名问题,即多个不同虚拟地址对应同一个物理地址。在这种映射关系下,通过a关系访存的修改也要同步到b关系。但是Cache的存在使得同步困难。
组相联的Cache才有同义问题。解决办法是对同义地址一起进行更新。
多Bank的Cache可以解决这个问题。读Cache的时候,查TLB得到物理地址,由中间几位索引选择一个cache bank输出。写Cache的时候,已经得到物理地址,直接选择特定bank进行写。缺点是输入负载大,读取功耗大。
同名问题是,一个虚拟地址可能对应不同的物理地址。在多进程的应用中可能存在这种情况。简单的解决方式是,切换进程时把Cache和TLB置为无效。但是清空缓存造成浪费。如果用PID/ASID扩展虚拟地址,就可以区分虚拟地址。但是需要额外的G位来标注共享地址。
过大的ASID会造成页表的浪费,此时可以使用三级页表。支持ASID的处理器会有专门的寄存器来保存ASID的值。
2.控制Cache
Cache的内容是物理内存的子集。
ARM使用协处理器管理Cache。MIPS使用软件指令管理Cache。
3.4.3 流水线上的Cache和TLB
1.PIPT
需要注意的前提是,tu此时必须经过VA到PA的转换。所以PIPT实际上是串行化了cpu到存储的访问。造成流水线深度的损耗,速度太慢(同频效率低)
如果Cache的大小小于offset的宽度,就可以把串行化的访问转换为并行。
2.VIPT
大多数处理器采用的方式。需要考虑三种情况,cache的寻址地址小于,等于,大于页的大小。
在小于等于页大小的情况下,cache查到的PT和TLB查到的PT相比较,决定是否命中。为了避免重名问题,cache单way的大小被限制在4KB,cache总的大小受到限制。
4kb的限制来源于操作系统/ISA对页大小的规范,在大于页大小的情况下,offset的一部分被虚拟地址编码,cache面临重名问题。重名指的是一个PA对应多个VA。
解决办法有2,多bank,或l2-cache。
前者在之前已经论述。后者的做法是,在L2-cache维护VA地址的a部分,a代表寻址地址和cache容量重合的部分。这样就可以凭a来寻址L1-cache当中已经同名的VA,使之clean,再把有效的data写入L1-cache。从而解决了同名问题。
3.VIVT
优点是,如果Cache命中,就不需要访问TLB。
仍然用L2-cache方法来解决重名问题,但是这次要维护完整的虚拟地址。
VIVT虽然速度快,但是也有歧义问题,即多个PA对应一个VA。解决方法是所有PA一起更新?代价太大了。
4.小结
如果TLB命中,则Cache,页表,页都会命中。否则就需要递归查询。
现代操作系统当中,发生缺页时,会切换进程以提高处理器的效率。